


让声音创作更简单(永久免费)
VoiceCraft 音创社是一款专业的 AI 音频处理桌面工具,主要功能是将文字转化为自然流畅的语音,并支持对已有音频进行变声处理。无论你是视频创作者、配音爱好者,还是需要对大量文本进行语音朗读,音创社都能帮你高效完成。
核心功能
📝 实时文字转语音(TTS)
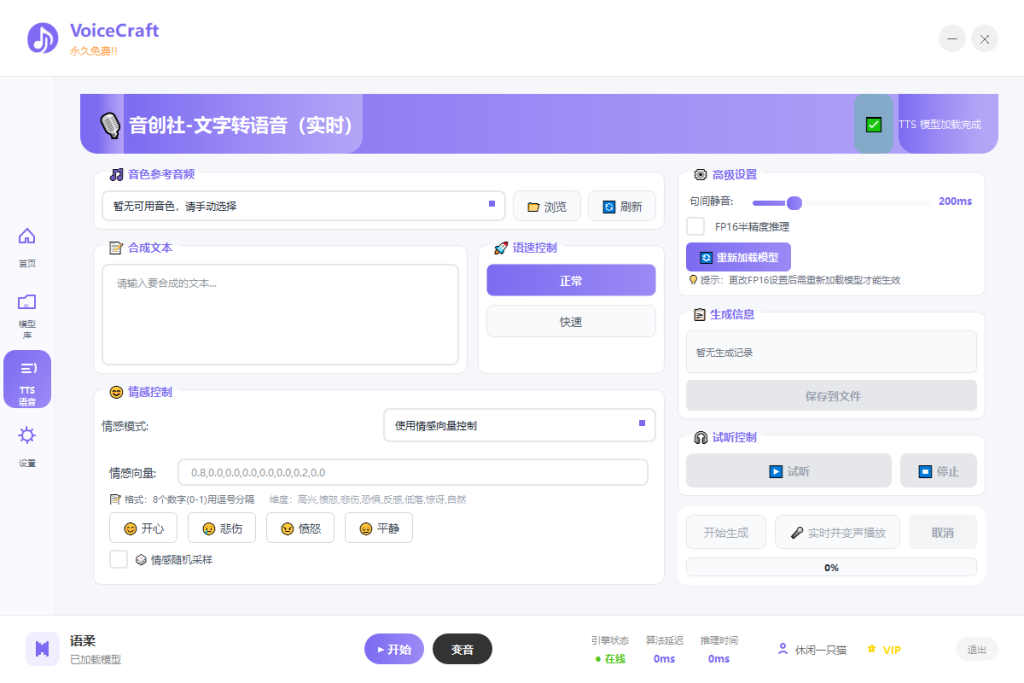
输入任意文字,选择一段参考音频作为目标音色,AI 即可用这个声音朗读你的文字。
- 操作简单:选择参考音频 → 输入文字 → 一键生成,无需任何训练
- 音色自然:生成的语音保留参考音频的音色、语调和说话风格
- 语速可调:支持正常语速和快速两档
- 情感控制:内置开心、悲伤、愤怒、平静等多种情感预设,也可手动调节情感强度
- 停顿可调:可以控制句子之间的停顿时长,让朗读更自然
- 音频格式:输出标准 WAV 音频,兼容所有音频编辑软件
适用场景:视频配音、有声书朗读、播客制作、学习资料语音化等。
🎤 实时变声(RVC)
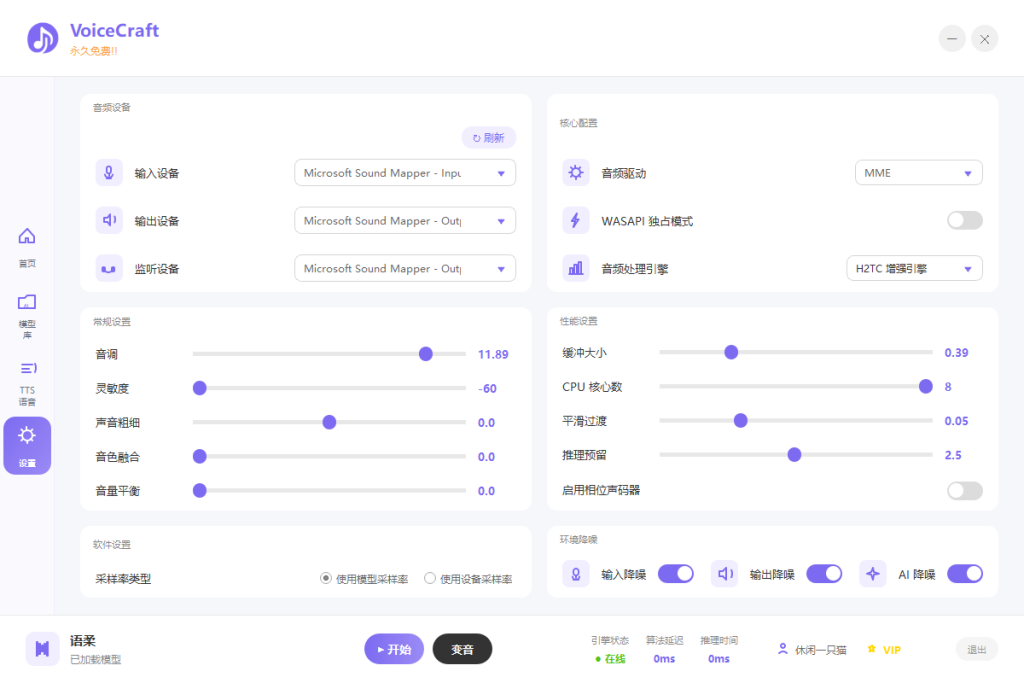
将一段音频里的人声转换为另一个目标音色的声音。
- 一键切换音色:加载声音模型后,输入音频即可获得目标音色的输出
- 音高自由调节:支持 ±12 个半音的音高调整,找到最适合的音域
- 多种变声算法:内置 6 种变声算法,可根据音频类型(说话/唱歌)选择最适合的效果
- 音色相似度增强:配合检索索引使用,音色还原更精准自然
- 实时预览:生成后可直接试听,不满意可重新调整参数
适用场景:声音美化、角色配音、虚拟形象直播、音乐制作等。
🔗 文字克隆语音TTS + 变声一键串联(无需讲话可以实时变声)
将”文字转语音”和”变声”两个步骤合二为一。输入文字,选择音色,AI 自动完成语音合成 + 变声处理,一步到位输出最终结果。
🎵 人声伴奏分离
从任意音乐文件中提取或去除人声、混响、回声。
- 人声提取:从歌曲中提取干净的人声轨道
- 去混响/去延迟:清除录音中的房间回声和延迟效果
- 多模式可选:针对不同音频质量匹配合适的处理模式
🗣️ 声音模型训练
如果内置的音色不能满足需求,你还可以训练自己的声音模型。
- 三步搞定:上传音频 → 设置参数 → 自动训练,无需复杂配置
- 模型融合:支持将两个音色混合,创造全新的声音
- 导出兼容:训练完成的模型可导出使用
功能特色
⚡ 高性能 GPU 加速
全面支持 NVIDIA 显卡加速,推理速度相比 CPU 提升数倍。同时支持最新的 RTX 50 系列显卡,新一代硬件也能发挥最佳性能。
💾 智能资源管理
模型采用懒加载设计,不占用启动时间闲置内存。5 分钟无操作自动释放显存,长期使用也流畅不卡顿。
🌐 13 种语言界面
支持简体中文、英语、日语、韩语、法语、德语、西班牙语、意大利语、葡萄牙语、俄语、土耳其语、粤语、新加坡华语共 13 种语言界面,切换方便。
🔒 安全自动更新
软件内置自动更新检测,有新版本时自动提醒。更新包经过完整性校验,确保安全可靠。
👥 单实例运行
智能检测是否已有程序在运行,避免重复启动导致的冲突问题。
适用人群
| 人群 | 用途 |
|---|---|
| 视频创作者 | 为视频快速配上自然旁白,多种音色可选 |
| 虚拟主播 | 实时变声,与虚拟形象完美匹配 |
| 音乐爱好者 | 人声分离、伴奏提取、音色训练 |
| 配音爱好者 | 多种音色体验,情感丰富可调 |
| 有声书主播 | 批量将文字转为语音,提高制作效率 |
| 语音研究者 | 完整训练推理平台,方便实验 |
快速上手
- 下载安装:下载打包好的可执行文件,双击即可运行,无需配置 Python 环境
- 选择音色参考:准备一段 5 秒以上的音频(WAV/MP3/FLAC 格式),作为目标音色
- 输入文字:在文本框输入要朗读的内容
- 点击生成:等待几秒,即可获得语音文件
- 试听保存:不满意可调整参数重新生成,满意则保存到本地
版本信息
当前版本:v1.2.9
VoiceCraft 音创社 —— 好声音,触手可及。
使用提示
下载模型文件后,您需要使用 音创社VoiceCraft 软件来加载并使用该模型。 请确保已正确安装,并将模型文件放置在指定的模型目录中。
开通钻石会员,即享一次模型免费定制服务 + 全站模型无限下载
免费资源
© 版权声明
THE END












暂无评论内容