


更新2026/01/01
本次我们正式发布H2TC版本底模,基于Spin框架进行优化,显著提升了模型的收敛速度,并对哑音现象进行了有效改进。
重要说明:由于打包时仅包含底模文件,请务必从ContentVec版本中获取48k.json配置文件与rmvpe.pt指导模型文件,并优先下载ContentVec版本的相关文件。
前言
H2TC底模为完全重新训练的预训练模型,不沿用任何RVC_v2默认底模参数。原RVC_v2模型基于109位说话人、50小时英文数据集训练。H2TC底模则采用ContentVec嵌入模型,使用总计超过100小时的中、英、日三语混合数据集进行预训练,并结合预训练的RMVPE模型提供高精度音高指导。
文件替换
请注意,因本模型扩展了说话人数量,您必须替换原RVC_v2底模的配置文件。
- 配置文件路径:
configs\v2\48k.json
(若您使用的是官方V1006版开源项目,该文件位置应一致。替换前建议备份原文件。)
- 配置文件路径:
- 同时请替换RMVPE模型文件:
assets\rmvpe\rmvpe.pt
- 同时请替换RMVPE模型文件:
训练模型时,必须完成以上两个文件的替换,否则将可能导致训练失败或输出声音沙哑。
模型参数
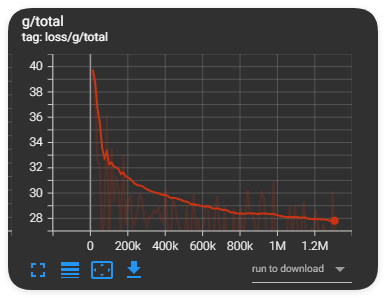
H2TC底模参数量约为RVC_v2底模的两倍,具体预训练信息如下:
- 说话人数量:429位
- 支持语言:中文 / 英文 / 日文
- 训练语料:>100小时
- 训练步数:约120万步
- 训练周期:65天
详细部署步骤
压缩包内包含以下文件:
- rmvpe.pt
- 48k.json
- D_H2TC-f048K.pth
- G_H2TC-f048K.pth
- 将 rmvpe.pt 与 48k.json 按上述”文件替换”步骤解压至对应路径。
- D_H2TC-f048K.pth 与 G_H2TC-f048K.pth 可存放于任意可访问目录。
- 完成以上操作后,H2TC底模即部署完毕。
训练设置
在训练界面中,请按顺序进行以下设置:
- 选择【目标采样率】→ 48K
- 分别修改【加载预训练底模G路径】与【加载预训练底模D路径】,指向对应的H2TC底模文件(.pth文件)。
(修改底模路径后)
训练过程中,若控制台输出以下信息:
DEBUG:infer.lib.infer_pack.models:gin_channels: 256, self.spk_embed_dim: 308
即表示底模已正确加载,所有步骤已完成。
常见问题排查
- 报错提示
[109,xxxx]
请返回”文件替换”步骤,确认 48k.json 已正确替换。
- 报错提示
- 高音部分输出沙哑
请确认 rmvpe.pt 已替换为新版指导模型。
- 高音部分输出沙哑
模型优势
- 有效抑制发音含糊现象
- 支持跨语种音色转换(例如日语转中文时不易出现”大佐音”,使用H2TC底模训练可显著改善)
- 仅需约6分钟语音数据即可取得良好训练效果
- 输出音色还原度更高
以上为H2TC新底模的完整部署指南,请按照步骤逐步操作即可顺利完成配置。
附:训练损失曲线图
(图略)
© 版权声明
THE END








暂无评论内容