


模型信息
| 特性维度 | 具体说明 |
|---|---|
| 核心定位 | 专注于高质量语音转换,通过精细调整实现特定的音色风格,如甜美、御姐等。 |
| 采样率 | 通常采用 48kHz 的高采样率,能记录更丰富的音频细节,提供接近CD级别的音质。 |
| 训练轮次 | 经过 “千轮” 级别的充分训练,有助于模型更好地学习数据特征,提升输出的准确性和自然度。 |
| 模型融合 | 可能运用了多模型融合技术,通过组合不同模型的优点,创造出独特或更平衡的复合音色。 |
💡 深入理解高端模型
除了表格中总结的要点,以下几个方面能帮助你更好地理解这类高端定制模型的价值:
-
🚀 48kHz采样率的优势:高采样率意味着在每秒钟内采集并处理更多的声音样本。这带来的直接好处是高频响应更好、声音细节更丰富,生成的语音听起来会更加通透和真实,非常适合音乐翻唱、广播剧等对音质要求高的创作场景。
-
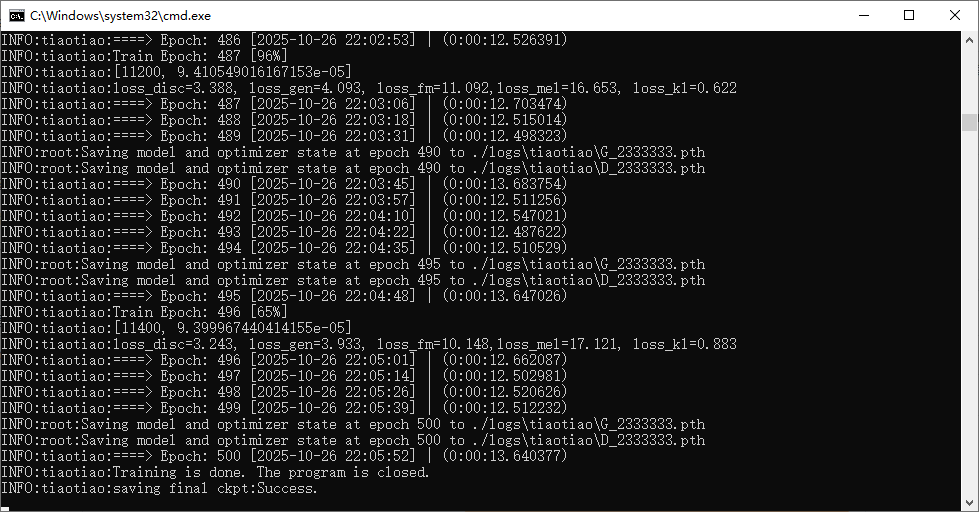
🧠 “千轮训练”意味着什么:在机器学习中,“轮”代表模型对整个训练数据集进行了一次完整学习。通常来说,更多的训练轮次意味着模型能够更充分地学习数据中的特征和模式。经过千轮训练的模型,在音色还原度、发音稳定性以及对复杂语句的处理能力上,通常会比快速训练的模型表现更优。
-
🎭 模型融合的创造力:这是高端模型定制中一项重要的技术。开发者可以将一个在“音色还原”上表现突出的模型,与另一个在“音质清晰度”上更胜一筹的模型进行融合。通过调整权重,可以创造出兼具两者优点的全新音色,甚至实现一些富有创意的声音效果。
| 模型算法 | Rmvpe |
| 唱歌高音 | 支持 |
| 支持语言 | 国语/英语 |
| 采样率 | 48k |
| 训练轮数 | 1000次 |
参数
| 响应阈值 | -60 |
| 采样长度 | 0.30 |
| harvest进程数 | 3 |
| 采样长度 | 0.70 |
| 额外推理时长 | 3.0 |
💨模型参数仅供参考需根据实际情况调整!
训练日志

试听
推理后
注意事项
付费资源
© 版权声明
THE END










暂无评论内容